HTTPie – command line HTTP client
Reading time: 1 – 2 minutes
I imagine you are used to using curl for many command line scripts, tests, and much more things. I did the same but some weeks ago I discovered HTTPie which is the best substitute that I’ve ever found for curl. Of course, it’s also available for a lot of Linux distributions, Windows, and Mac. But I used it with docker which is much more transparent for the operative system and easy to update. To be more precise I use next alias trick for using this tool:
alias http='sudo docker run -it --rm --net=host clue/httpie'
Official website: httpie.org
Let me paste some highlights about HTTPie:
- Sensible defaults
- Expressive and intuitive command syntax
- Colorized and formatted terminal output
- Built-in JSON support
- Persistent sessions
- Forms and file uploads
- HTTPS, proxies, and authentication support
- Support for arbitrary request data and headers
- Wget-like downloads
- Extensions
- Linux, macOS, and Windows support
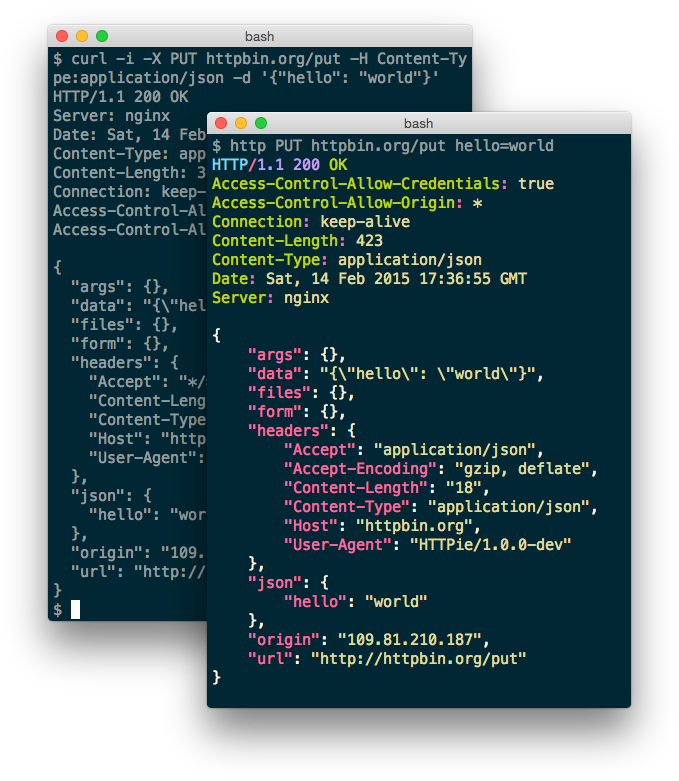
From the tool webpage a nice comparison about how HTTPie looks like versus curl.