Tired of updating documentation across multiple platforms? If your projects rely on Notion for planning and GitHub for collaboration, you might find yourself constantly re-copying information from your repository to your Notion pages.
This handy command-line tool allows you to sync your Markdown files directly to Notion, saving time and keeping everything in one place.
Why Syncing Docs with Notion Matters
Many businesses, freelancers, and creators rely on Notion for organizing their workflows and GitHub for managing code and documentation. But each time your repository changes, your Notion page can easily fall out of date, creating a disconnect between your development work and your project documentation. readme2notionbridges this gap by automatically updating your Notion pages with the latest content from your repositories. You get an always-up-to-date Notion page that syncs with your codebase, so everyone on your team has the latest info in real time.
What is readme2notion?
At its core, readme2notion is a command-line tool that takes a Markdown file, converts it into Notion blocks, and uploads the content to a specified Notion page. This tool is versatile, finding the appropriate Notion page by name or creating one if it doesn’t exist. Once set up, it can transform your Markdown files into well-organized Notion pages with just one command.
How readme2notionWorks
Markdown Conversion: The tool reads your Markdown file and converts it into Notion-friendly blocks.
Upload and Sync: It then uploads the converted content to a Notion page, either updating an existing page or creating a new one based on the settings you choose.
Automated Updates: With a pre-push hook, readme2notion can automate the process, so every time you push a new change to your repository, your Notion page stays updated without any extra effort.
Key Features of readme2notion
Simple Conversion: Easily converts Markdown text into Notion’s block-based format.
Automatic Page Updates: Finds or creates the appropriate Notion page in the database you specify, meaning your docs are always up-to-date.
Pre-Push Hook: This feature allows for completely automated updates to Notion. With every push, your Notion page gets a fresh update, making it perfect for remote teams or anyone who needs a reliable source of truth for documentation.
Why You Should Try readme2notion
Updating Notion pages by hand can be tedious, especially if you’re a developer or creator juggling multiple projects. This tool eliminates the hassle by letting you write documentation once in your repository’s README file and automatically reflecting those changes in Notion. Plus, readme2notionworks seamlessly within your existing Git workflows, allowing your team to focus on what matters—building and creating—while staying informed and organized.
If your documentation process could use an upgrade, give readme2notiona try. It’s the easiest way to ensure your Notion workspace always reflects the latest state of your codebase.
OpenWRT, the popular open-source Linux operating system designed for embedded devices, offers the LUCI interface for easy configuration and management. LUCI is essentially the web interface for OpenWRT, and while it’s already feature-rich, sometimes you may want to extend its functionalities based on your needs.
Recently, I had a requirement to enhance my OpenWRT LUCI interface. Specifically, I wanted to introduce a new menu named “Apps” in the LUCI dashboard. The objective was to have each entry within this new menu link to different applications installed on my device. And not just that! I wanted these application pages to pop open in new tabs for ease of access.
The Solution
The changes were made in a single file located at:
/usr/lib/lua/luci/controller/apps.lua
Within this file, I implemented the following code:
module("luci.controller.apps", package.seeall)function index() local page page =entry({"admin","apps"},firstchild(),_("Apps"),60) page.dependent = falseentry({"admin","apps","portainer"},call("serve_js_redirect","https","9443"),_("Portainer"),10).leaf = trueentry({"admin","apps","nodered"},call("serve_js_redirect","http","1880"),_("NodeRED"),20).leaf = trueentry({"admin","apps","grafana"},call("serve_js_redirect","http","3000"),_("Grafana"),30).leaf = trueentry({"admin","apps","prometheus"},call("serve_js_redirect","http","9090"),_("Prometheus"),40).leaf = trueendfunction serve_js_redirect(protocol, port) local ip = luci.http.getenv("SERVER_ADDR") local url = protocol .."://" .. ip ..":" .. port luci.http.prepare_content("text/html; charset=utf-8") luci.http.write("<!DOCTYPE html><html><head><meta charset='UTF-8'><title>Redirecting...</title></head><body>") luci.http.write("<script type='text/javascript'>") luci.http.write("window.onload = function() {") luci.http.write(" var newWindow = window.open('".. url .."', '_blank');") luci.http.write(" if (!newWindow || newWindow.closed || typeof newWindow.closed == 'undefined') {") luci.http.write(" document.getElementById('manualLink').style.display = 'block';") luci.http.write(" setTimeout(function() { window.location.href = document.referrer; }, 60000);")-- Redirigir después de 60 segundos luci.http.write(" }") luci.http.write("}") luci.http.write("</script>") luci.http.write("<p id='manualLink' style='display: none;'>The window didn't open automatically. <a href='".. url .."' target='_blank'>Click here</a> to open manually.</p>") luci.http.write("</body></html>")end
Key Points
The index function is responsible for defining the new menu and its entries.
The serve_js_redirect function creates a web page that uses JavaScript to automatically open the desired application in a new browser tab.
A failsafe mechanism is added in the form of a link. If, for any reason (like pop-up blockers), the new tab doesn’t open automatically, the user has the option to manually click on a link to open the application.
The script also includes a feature that will redirect the user back to the previous page after 60 seconds if the new tab doesn’t open.
This modification provides a seamless way to integrate external applications directly into the LUCI interface, making navigation and management even more convenient!
Reading time: < 1 minute
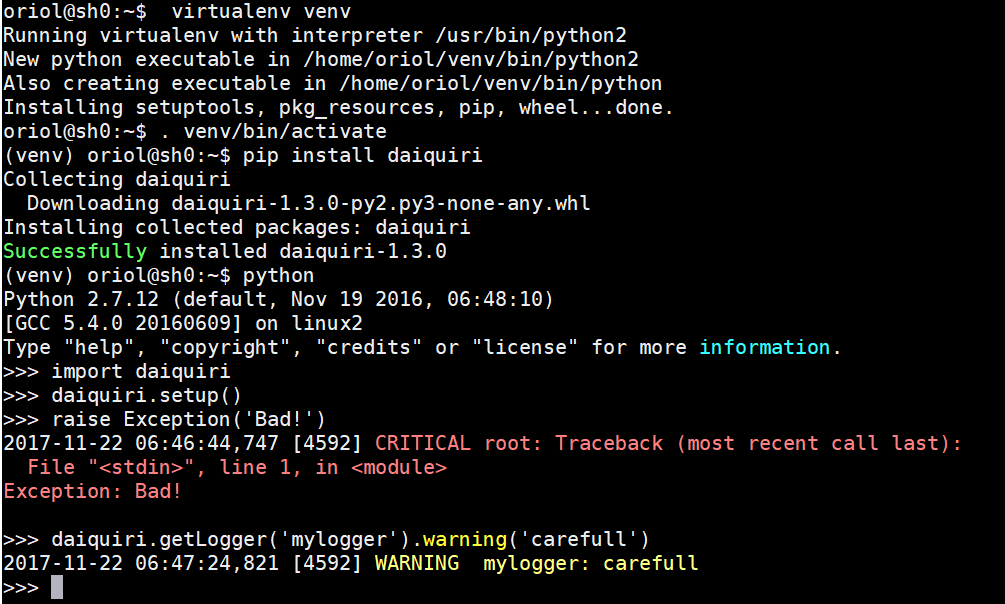
Python logging library is really flexible and powerful but usually, you need some time for setting up the basics or just for logging in a simple script, some commands and settings have to be done. Daiquiri is a library which wrapper python logging library and offers a simple interface for start enjoying logging features in python. Next, there is a hello world example extracted from Daiquiri documentation which shows how easy it gets nice output from the console when you're programming simple scripts.
This week I finished this course from MIT. After my previous experience on MIT professional courses, I decided to involved in a new one. I know it sounds strange after my really bad feedback in my previous course about IoT, but I decided to give a second opportunity to this kind of courses.
My general opinion about this course is by far better than the previous one, so I’m happy to be done this course. I learn a lot, and of course now is time to put knowledge in practice, so it’s not a minor thing to do. Talking about the difficulty of the course I found two initial modules especially difficult, a lot of mathematics and formulas and it was very difficult to follow explanations because of the complexity of the concepts and mathematical formulas which describe them. In my case some code in any programming language using libraries which abstract mathematical formula complexity would be ideal.
About those two initial modules: “Making sense of unstructured data” and “Regression and Prediction” perhaps the subjects sounds good especially where I want to apply the knowledge, so in IIoT, this is not easy to figure out how to apply that knowledge in time series data. Maybe the best thing that I get from there is what are the main algorithms and theoretical basis that I have to apply in real world projects.
The third module has the subject “Classification, Hypothesis and Deep Learning” and it’s very linked with the previous, by the way, I found easier to understand the related mathematics and how to apply that knowledge. I especially found easy to understand and interesting to apply in IIoT the deep learning chapter, some concepts and basic ideas about neuronal networks are described in a very easy way and graphical synoptic and animations help a lot on following the concepts.
The last two modules about “Recommendation systems” and “Networks and Graphical Models” are presented in a very useful way, very applied to real world and with a lot of examples and I appreciate it. Apart from that teachers did a very good work explaining together and being very progressive in complexity from the bottom up.
If I have to suggest any improvement would be in the practical part, I consider Python a programming language with better future in Data Scientist world than R, may be R has a very good base and history as a language for scientists but I think tools like Jupyter has a better future than legacy tools like RStudio. So get more details and references about how to play with Python based tools and libraries than focus on R would be my recommendation.
Another point to improve, in my opinion, would be add some videos dedicated to using tools and how to apply those tools in case studies. At the end of the day, screencast videos are super useful when you’re not familiar with some technologies.
Summarizing I recommend the course, but don’t expect any fast application of the knowledge is a very theoretical course to get the basics and later get practical skills from your side with case studies or other references.
Last Thursday I participated in a round table about Industry 4.0 as part of the Catalan Telecommunications Day, really interesting event in a very nice place. I haven’t been in Cosmo Caixa since it was called “Museu de la Ciència” a very long time ago. But I have to say that the place is very trendy and awesome.
Coming back to the event, I met some good friends and it’s always a pleasure but I also meet very interesting new people with who I’ll be happy to keep on talking and going deep on aligning synergies. One of those are i2cat people, guys we have to find the proper way to collaborate because again and again we meet each other with very compatible points of view.
About the content of my exposition I want to remark two things:
Firstly I think we have the debt to leadership the fourth industrial revolution, and catch up all those companies that never did the third revolution no the present. Catalonia has very powerful minds with a lot of entrepreneurs now it’s time to work together and demonstrate what we can do.
Secondly summarize the Fernando Trías de Bes article in “La Vanguardia”
In the 90s they said that Internet is going to be like another TV channel in our TVs; companies only need to create a Web page and they are ready for the future. But in the end it changed the ‘P’ of product in the marketing strategy.
Early 2000 e-commerce get it real and they said that it’s only another distribution channel, but finally it has been the change of two ‘P’s point of sale and price, both of them became obsolete.
In 2006 the revolution come through the social networks, they said only this is only personal webs instead of enterprise web; just create some accounts in those social networks and that’s all. But ‘P’ of promotion has been redefined with new market segmentation.
Since 2010 smartphones sales increased dramatically and they said this is just like a mini PC, just adapt web pages and everything is done. But a lot of markets disappeared or changed deeply: photo cameras, music CDs, telephony, etc. So ‘P’ of point of sale and ‘P’ of product totally redefined. Virtual and physical experiences unified.
First decade of new century Internet 2.0 has been consolidated, they said this is just web where people can participate. Companies only need to add a corner in their webpages where can discuss. ‘P’ of prices digital money and a lot of new business models.
Currently we talk about IoT and they say this is about adding electronics to the physical world. Instead of that what happen is all product in a digital environment tends to be converted in a service. Again the ‘P’ of product is obsolete and has to be totally redefined.
Having that in mind IMHO we have huge opportunities within reach.
signature: is calculated with the next formula, given a “seed”
seed = “This is just a random text.”
str = customer_id + expire_date + path_n_file
signature = encode_base64( hmac_sha1( seed, str))
customer_id: just an arbitrary identifier when you want to distinguish who use the URL
expire_date: when the generated URL stops working
path_n_file: relative path in your private repository and the file to share
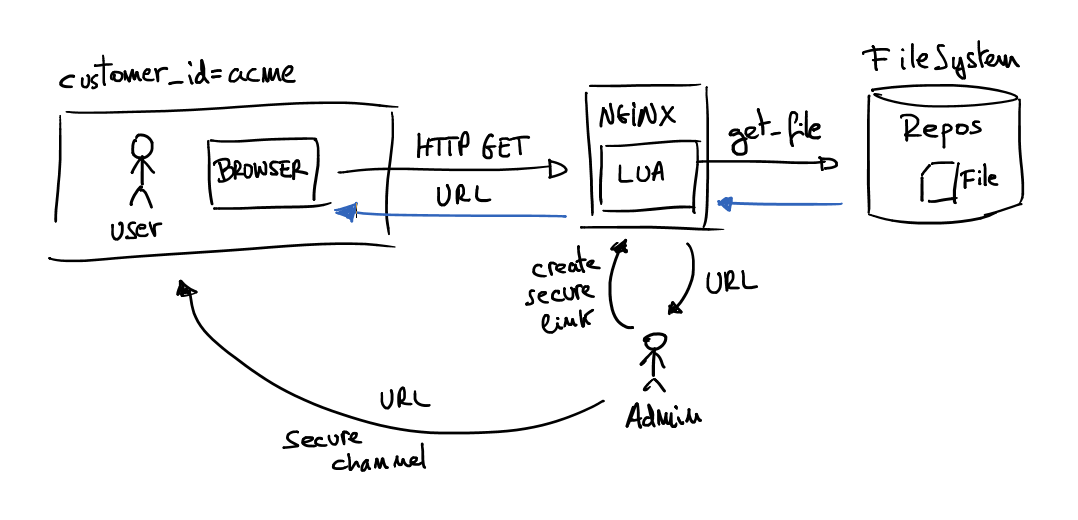
Understanding the ideas explained before I think it’s enough to understand what is the goal of the solution. I developed the solution using NGINX and LUA. But the NGINX version used is not the default version is a very patched version called Openresty. This version is specially famous because some important Chinese webs works with that, for instance, Taobao.com
In the above schema there is a master who wants to share a file which is in the internal private repository, but the file has a time restriction and the URL is only for that customer. Then using the command line admin creates a unique URL with desired constrains (expiration date, customer to share and file to share). Next step is send the URL to the customer’s user. When the URL is requested NGINX server evaluates the URL and returns desired file only if the user has a valid URL. It means the URL is not expired, the file already exists, the customer identification is valid and the signature is not modified.
This is the server part of the NGINX configuration file, the rest of the file can as you want. Understanding this file is really simple, because the “server_name” works as always. Then only locations command are relevant. First “location” is just a regular expression which identifies the relevant variables of the URL and passes them to the LUA script. All other URLs that doesn’t match with the URI pattern fall in path “/” and the response is always “Forbiden” (HTTP 403 code). Then magics happen all in LUA code.
LUA scripts
There are some LUA files required:
create_secure_link.lua: creates secure URLs
get_file.lua: evaluates URLs and serves content of the required file
lib.lua: module developed to reuse code between other lua files
sha1.lua: SHA-1 secure hash computation, and HMAC-SHA1 signature computation in Lua (get from https://github.com/kikito/sha.lua)
It’s required to configure “lib.lua” file, at the beginning of the file are three variables to set up:
lib.secret = "This is just a long string to set a seed"lib.base_url = "http://downloads.local/"lib.base_dir = "/tmp/downloads/"
Create secure URLs is really simple, take look of the command parameters:
$ ./create_secure_link.lua ./create_secure_link.lua <customer_id><expiration_date><relative_path/filename>Create URLs with expiration date. customer_id: any string identifying the customer who wants the URL expiration_date: when URL has to expire, format: YYYY-MM-DDTHH:MM relative_path/filename: relative path to file to transfer, base path is: /tmp/downloads/
Run example:
$ mkdir -p /tmp/downloads/dir1$ echo hello > /tmp/downloads/dir1/example1.txt$ ./create_secure_link.lua acme 2015-08-15T20:30 dir1/example1.txthttp://downloads.local/YjZhNDAzZDY0/acme/2015-08-15T20:30/dir1/example1.txt$ dateWed Aug 12 20:27:14 CEST 2015$ curl http://downloads.local:55080/YjZhNDAzZDY0/acme/2015-08-15T20:30/dir1/example1.txthello$ dateWed Aug 12 20:31:40 CEST 2015$ curl http://downloads.local:55080/YjZhNDAzZDY0/acme/2015-08-15T20:30/dir1/example1.txtLink expired
Some times schemas and snippets don’t need large descriptions. If you think this is not enough in this case tell me and I’m going to add explanations.
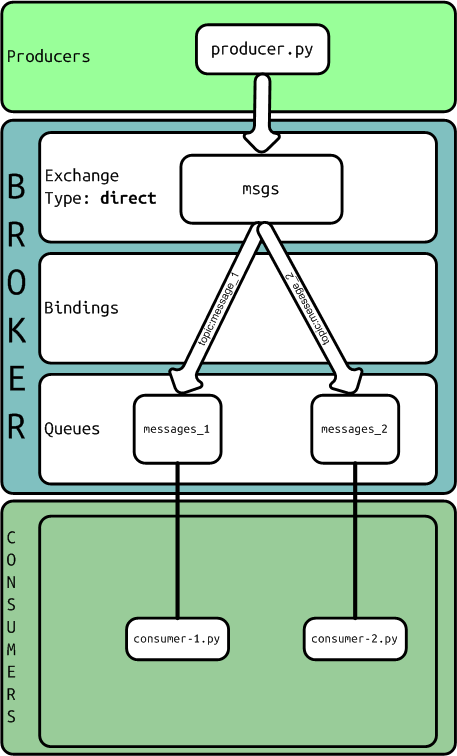
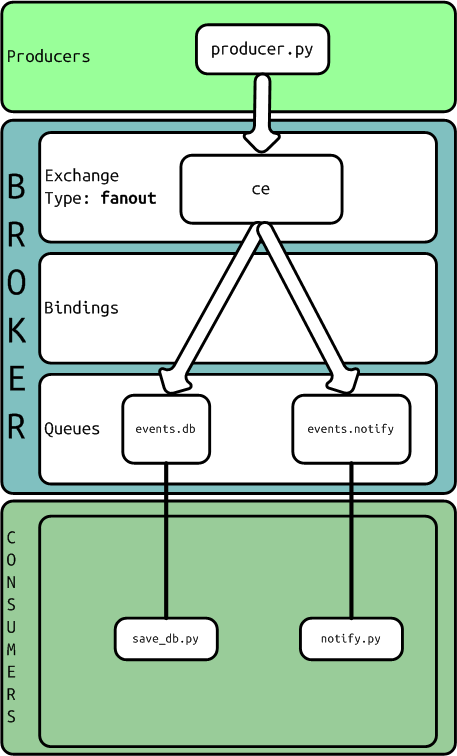
Using a python library called kombu as an abstraction to talk with AMQP broker we are going to develop different message routes setting each type of Exchange. As a backend I used RabbitMQ with default configuration.
Kombu implements SimpleQueue and SimpleBuffer as simple solution for queues with exchange of type ‘direct’, with the same exchange name, routing key and queue name.
Pusher:
from kombu import BrokerConnectionconnection = BrokerConnection("amqp://guest:guest@localhost:5672//")queue = connection.SimpleQueue("logs")payload = { "severity":"info", "message":"this is just a log", "ts":"2013/09/30T15:10:23" }queue.put(payload, serializer='pickle')queue.close()
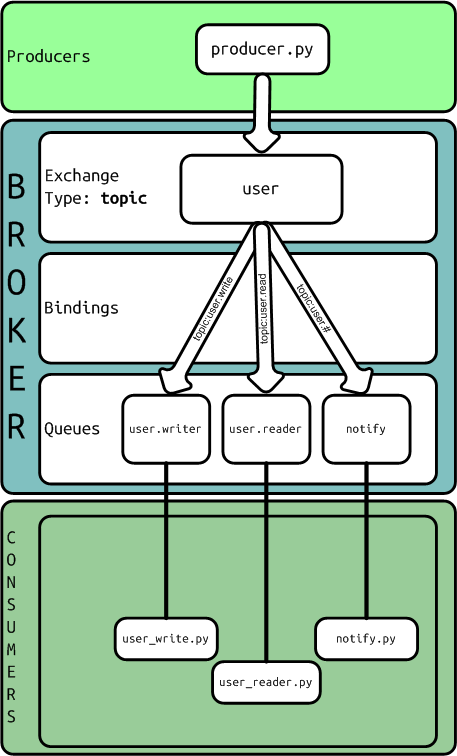
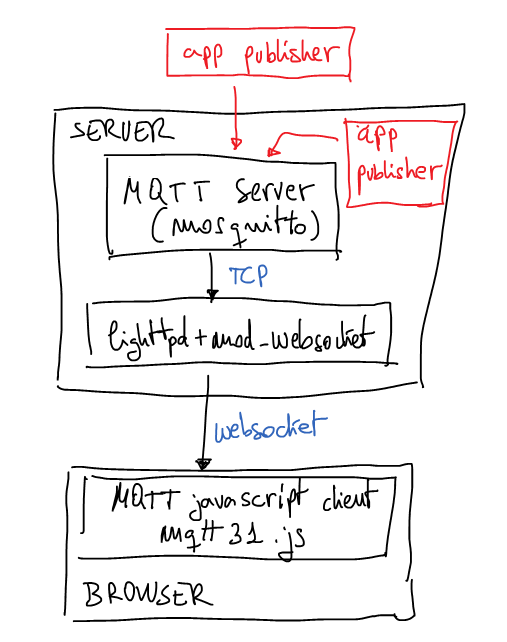
Nowadays last version of browsers support websockets and it’s a good a idea to use them to connect to server a permanent channel and receive push notifications from server. In this case I’m going to use Mosquitto (MQTT) server behind lighttpd with mod_websocket as notifications server. Mosquitto is a lightweight MQTT server programmed in C and very easy to set up. The best advantage to use MQTT is the possibility to create publish/subscriber queues and it’s very useful when you want to have more than one notification channel. As is usual in pub/sub services we can subscribe the client to a well-defined topic or we can use a pattern to subscribe to more than one topic. If you’re not familiarized with MQTT now it’s the best moment to read a little bit about because that interesting protocol. It’s not the purpose of this post to explain MQTT basics.
A few weeks ago I set up the next architecture just for testing that idea:
weboscket gateway to mosquitto mqtt server with javascrit mqtt client
The browser
Now it’s time to explain this proof of concept. HTML page will contain a simple Javascript code which calls mqttws31.js library from Paho. This Javascript code will connect to the server using secure websockets. It doesn’t have any other security measure for a while may be in next posts I’ll explain some interesting ideas to authenticate the websocket. At the end of the post you can download all source code and configuration files. But now it’s time to understand the most important parts of the client code.
Last part is very simple, the client connects to the server and links some callbacks to defined functions. Pay attention to ‘useSSL’ connect option is used to force SSL connection with the server.
There are two specially interesting functions linked to callbacks, the first one is:
function onConnect() { client.subscribe("/news/+/sport", {qos:1,onSuccess:onSubscribe,onFailure:onSubscribeFailure});}
As you can imagine this callback will be called when the connections is established, when it happens the client subscribes to all channels called ‘/news/+/sports’, for example, ‘/news/europe/sports/’ or ‘/news/usa/sports/’, etc. We can also use, something like ‘/news/#’ and it will say we want to subscribe to all channels which starts with ‘/news/’. If only want to subscribe to one channel put the full name of the channel on that parameter. Next parameter are dictionary with quality of service which is going to use and links two more callbacks.
The second interesting function to understand is:
function onMessageArrived(message) { console.log("onMessageArrived:"+message.payloadString);};
It’s called when new message is received from the server and in this example, the message is printed in console with log method.
The server
I used an Ubuntu 12.04 server with next extra repositories:
After installation it’s very easy to run mosquitto in test mode, use a console for that and write the command: mosquitto, we have to see something like this:
# mosquitto1379873664: mosquitto version 1.2.1 (build date 2013-09-19 22:18:02+0000) starting1379873664: Using default config.1379873664: Opening ipv4 listen socket on port 1883.1379873664: Opening ipv6 listen socket on port 1883.
The configuration file for lighttpd in testing is:
Remember to change ‘ssl.pemfile’ for your real certificate file and ‘server.name’ for your real server name. Then restart the lighttpd and validate SSL configuration using something like:
openssl s_client -host ns.example.tld -port 443
You have to see SSL negotiation and then you can try to send HTTP commands, for example: “GET / HTTP/1.0” or something like this. Now the server is ready.
The Test
Now you have to load the HTML test page in your browser and validate how the connections is getting the server and then how the mosquitto console says how it receives the connection. Of course, you can modify the Javascript code to print more log information and follow how the client is connected to MQTT server and how it is subscribed to the topic pattern.
If you want to publish something in MQTT server we could use the CLI, with a command mosquitto_pub:
mosquitto_pub -h ns.example.tld -t '/news/europe/sport' -m 'this is the message about european sports'
Take a look in your browser Javascript consle you have to see how the client prints the message on it. If it fails, review the steps and debug each one to solve the problem. If you need help leave me a message. Of course, you can use many different ways to publish messages, for example, you could use python code to publish messages in MQTT server. In the same way you could subscribe not only browsers to topics, for example, you could subscribe a python code:
Pay attention to server port, it isn’t the ‘https’ port (443/tcp) because now the code is using a real MQTT client. The websocket gateway isn’t needed.
The files
mqtt.tar.gz – inside this tar.gz you can find all referenced files
Last weekend I worked on setting up home heaters using Panstamp. Panstamp is an Arduino board with Texas Instruments radio. Next winter we’re going to control our home heater using connected internet devices like the laptop, tablet o mobile phones. In this post I only want to share some pictures about the process to install the electronics inside the heaters changing the old electronic boards with new custom ones.
The parts:
AC/DC transformer, outputs 5V. It’s really cheap, in this case free because I have more than 20 of them from old projects.
A small custom PCB designed and made by Daniel Berenguer, the owner of Panstamp. Thanks again Daniel. I bought the PCBs and parts for around 10€ each one.
TMP36 temperature sensor. It costs about 1,5€ each one.
Solid state relay (SSR) bought in Alied Express web site for less than 5€.
The process:
I used a lot of tools, because DIY aren’t my strong hability.
Double-head tape and hot-blue gun are need…
because I want to use a cork base under the PSU and PCB
Parallelization of the last process Using a cutter I got the units SSR setup connecting SSR, PCB and PSU assembling everything on heater side panel finally, mounting side panel on the heater
Next weeks, I’ll come back with this subject to talk about the software part.
 This week I finished
This week I finished