Avui en faig 48
Avui compleixo 48, i si alguna cosa m’ha ensenyat el temps és que l’experiència no arriba només amb els anys, sinó amb les vivències que ens transformen.
Fa molt vaig entendre que la vida no et dona manuals. Et dona moments. I alguns d’ells et trenquen per dins… però també són els que t’ajuden a créixer de veritat.
– La mort del meu pare va ser el primer gran cop. Ho recordo en detalls petits, invisibles per als altres però inesborrables per a mi. Encara avui, qualsevol gest quotidià pot portar-me la seva imatge.
– L’accident de cotxe va marcar el final de la meva adolescència i l’inici d’una nova manera de veure el món.
– La pèrdua del meu fill Pol ha estat, sens dubte, l’experiència més dura. Encara avui, recordar-ho m’omple els ulls de llàgrimes… però també m’ha ensenyat a valorar i agrair cada instant amb més intensitat.
Amb els anys he après a mirar la vida com un rellotge de sorra.
La sorra que ja ha caigut ha perdut el seu color original: s’ha convertit en experiència.
I la que queda a dalt… ja no té l’energia dels 20 anys. Als 48, aquesta energia canvia, però gana en consciència, en sentit, en profunditat.
El pas del temps no és lineal, ni just, ni previsible. Però sí que podem triar com mirar-ho: amb nostàlgia o amb gratitud.
Jo he triat agrair.
He triat construir.
I, sobretot, he triat ser fidel a mi mateix.
La vida no va de trobar-se, va de crear-se.
I sí, avui avui m’he llevat a les 5 del matí per a escriure això, perquè em recorda qui soc, d’on vinc i tot el que encara em queda per viure.
Gràcies a totes les persones que m’heu acompanyat en aquest viatge.
La millor recompensa? La família que hem creat Estefania i jo, que s’ha convertit en el Sol al voltant del qual gira tot.

Avui, més que mai, em sento plenament autor d’aquesta obra que anomenem vida.
#FeliçAniversari #CreixementPersonal #Gratitud #PNL #Experiència #Feliços48 #Tete i #Fàtima
Implementing Per-Domain DNS Configuration on Linux Ubuntu Using dnsmasq
In Linux, managing network traffic is essential for a robust and secure IT infrastructure. In this post, we focus on Ubuntu—whether running on a virtual machine, Windows Subsystem for Linux (WSL), or a physical machine running Ubuntu 24.04. We will configure per-domain DNS rules using dnsmasq. This guide also covers additional considerations for WSL and systems using netplan.
Configuring Ubuntu for Local DNS with dnsmasq
When using Ubuntu, you might be using netplan for network configuration. In that case, you need to configure netplan to use the local DNS server provided by dnsmasq. Make sure your netplan configuration (e.g., /etc/netplan/01-netcfg.yaml) sets the DNS to 127.0.0.1, so that all DNS queries are forwarded to your local dnsmasq server.
Disabling systemd-resolved
Ubuntu often uses systemd-resolved by default, which can interfere with your custom DNS setup. To prevent conflicts, disable and stop systemd-resolved using the following commands:
sudo systemctl disable systemd-resolved
sudo systemctl stop systemd-resolved
sudo systemctl daemon-reload
This ensures that systemd-resolved does not override your DNS settings.
Note for WSL Users
If you are running Ubuntu under WSL, you need to prevent WSL from overwriting your DNS settings. Edit or create the file /etc/wsl.conf with the following content:
[network]
generateResolvConf = false
Then, create or edit the /etc/resolv.conf file to include:
nameserver 127.0.0.1
This ensures that your system uses the local dnsmasq server.
Installing and Setting Up dnsmasq
Step 1: Install dnsmasq
First, update your package list and install dnsmasq:
sudo apt update
sudo apt install dnsmasq
Step 2: Enable and Verify the dnsmasq Service
After installing dnsmasq, enable the service and check its status to ensure it is running correctly:
sudo systemctl enable dnsmasq
sudo systemctl daemon-reload
sudo systemctl start dnsmasq
sudo systemctl status dnsmasq
You should see that dnsmasq is active and running. This local DNS server will be used to resolve all DNS queries forwarded from your system.
Step 3: Configure dnsmasq
Edit the /etc/dnsmasq.conf file to set up your DNS rules. Here’s an example configuration:
# Default upstream DNS servers
server=8.8.8.8
server=8.8.4.4
# Domain-specific DNS servers
server=/domain01.tld/172.30.0.1
server=/domain02.tld/172.30.0.2
Explanation:
- The lines
server=8.8.8.8andserver=8.8.4.4set Google’s public DNS as the default upstream DNS servers. When a query does not match any domain-specific rule, dnsmasq will forward the request to these servers. - The lines
server=/domain01.tld/172.30.0.1andserver=/domain02.tld/172.30.0.2specify that queries for any host withindomain01.tldanddomain02.tldshould be resolved by the DNS servers at172.30.0.1and172.30.0.2, respectively.
After making your changes, save the file and restart dnsmasq to apply the new configuration:
sudo systemctl restart dnsmasq
Verifying the DNS Configuration
You can use the dig command to verify that your DNS rules are working as expected. Note that when your system’s resolver is set to use dnsmasq at 127.0.0.1, the dig output will always show SERVER: 127.0.0.1#53. However, dnsmasq will forward the query internally to the appropriate upstream DNS server based on your configuration.
Below are two examples: one for a public domain (google.com) and one for a domain that should be resolved by your custom DNS rule (example01.tld).
Example 1: Verifying a Public Domain (google.com)
Run the following command:
dig google.com
Simulated Output:
; <<>> DiG 9.11.3-1ubuntu1-Ubuntu <<>> google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 12345
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; QUESTION SECTION:
;google.com. IN A
;; ANSWER SECTION:
google.com. 300 IN A 172.217.164.110
google.com. 300 IN A 172.217.164.78
;; Query time: 23 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Wed Feb 20 10:00:00 UTC 2025
;; MSG SIZE rcvd: 113
Internal Process:
- Step 1: The query for
google.comis sent to the local dnsmasq server at127.0.0.1. - Step 2: dnsmasq examines its configuration and sees that
google.comdoes not match any domain-specific rules. - Step 3: It then forwards the query to the default upstream DNS servers (
8.8.8.8and8.8.4.4). - Step 4: The upstream server resolves
google.comand returns the result back to dnsmasq, which then passes it back to the client.
Example 2: Verifying a Domain with a Custom DNS Rule (example01.tld)
Run the following command:
dig example01.tld
Simulated Output:
; <<>> DiG 9.11.3-1ubuntu1-Ubuntu <<>> example01.tld
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 67890
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; QUESTION SECTION:
;example01.tld. IN A
;; ANSWER SECTION:
example01.tld. 60 IN A 172.30.0.1
;; Query time: 25 msec
;; SERVER: 127.0.0.1#53(127.0.0.1)
;; WHEN: Wed Feb 20 10:00:10 UTC 2025
;; MSG SIZE rcvd: 82
Internal Process:
- Step 1: The query for
example01.tldis sent to dnsmasq at127.0.0.1. - Step 2: dnsmasq checks its configuration and finds a matching domain-specific rule for
example01.tld, which directs the query to the DNS server at172.30.0.1. - Step 3: dnsmasq forwards the query internally to
172.30.0.1without exposing this step in the client’s dig output. - Step 4: The upstream server at
172.30.0.1resolves the query, and dnsmasq returns the answer to the client.
In both cases, while the client sees the query being handled by 127.0.0.1, dnsmasq intelligently directs the queries to the appropriate upstream servers based on your configuration. This seamless internal forwarding is what allows you to manage per-domain DNS resolution effectively.
Conclusion: Why Use Per-Domain DNS Configuration?
Implementing per-domain DNS configuration on Linux Ubuntu is a powerful way to gain granular control over your network’s behavior. This approach is particularly useful for:
- Enterprise Environments: Where internal domains require different DNS resolutions from external queries.
- Development and Testing: Allowing developers to redirect domain requests to local or test servers.
- Security: Enhancing network security by segregating traffic and reducing reliance on external DNS servers.
By configuring dnsmasq with domain-specific rules and ensuring that your system points to the local DNS (especially important when using netplan or running under WSL), you optimize network performance and security tailored to your specific needs.
Web-based Swagger API documentation and client
For example, we use NPM (Nginx Proxy Manager). The Web User Interface (WUI) of NPM relies on a backend API. By inspecting your browser’s network requests, you can observe how it functions.
However, I was unable to find comprehensive documentation for this API. With a bit of research, you can discover that the NPM API exposes its schema in a specific location:
https://npm.your-domain.tld/api/schemaIf you’re looking for a convenient web-based API client along with a documented interface to help you understand how to use it, simply run the following Docker container:
docker run -p 80:8080 -d swaggerapi/swagger-uiOpen your browser and navigate to http://localhost, and you will see something like this:
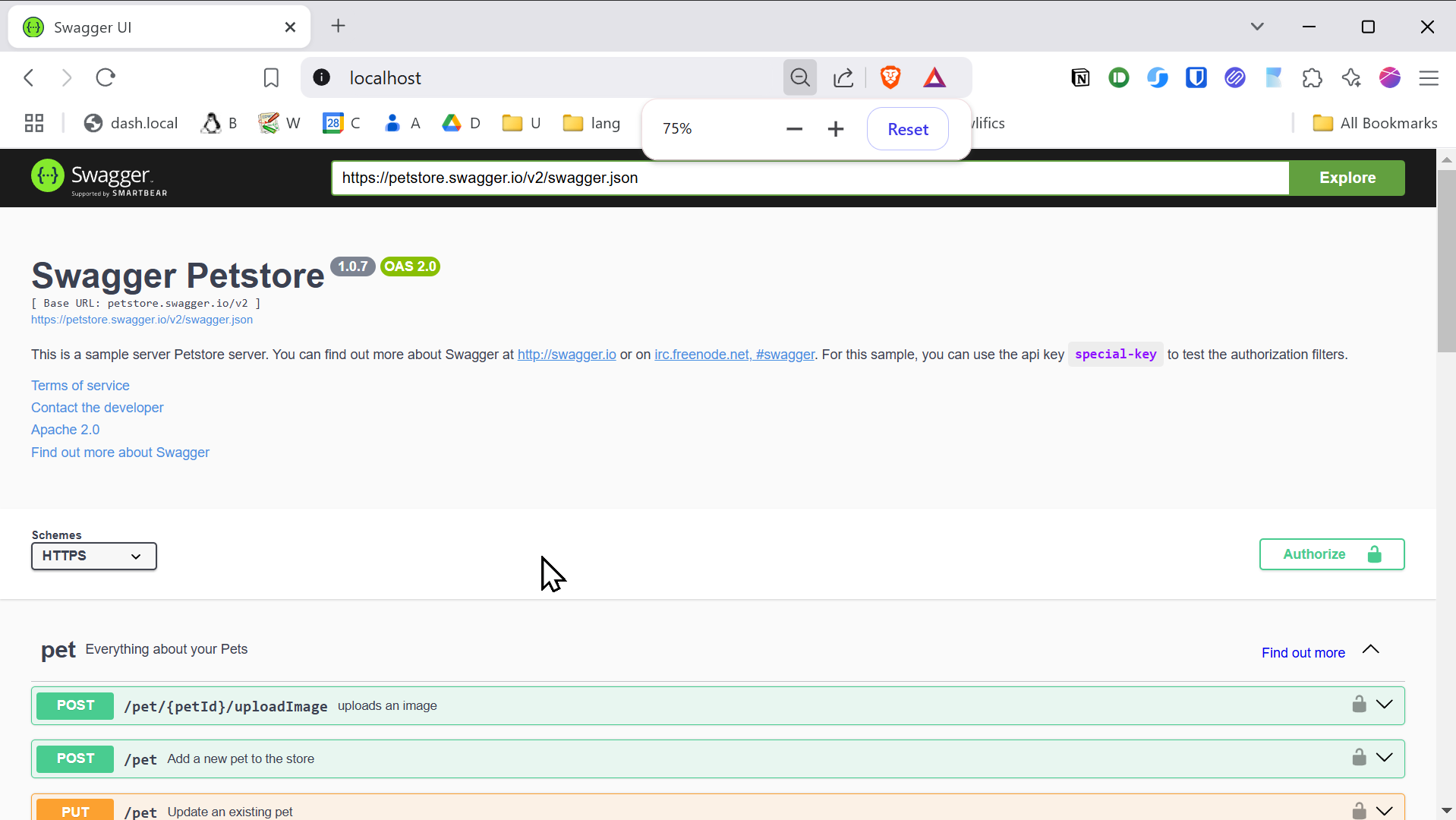
Finally, replace the Petstore API URL with your own, such as https://npm.your-domain.tld/api/schema, or any OpenAPI URL you wish to use.
Below is a screenshot of my local NPM setup:

I hope this post has been helpful to you. Thank you for taking the time to read it.
Formatos de Certificados: PEM, DER y PKCS#12 y Manipulación de Claves Privadas
Serie
- Gestión de certificados (PKI) – easy-rsa
- MQTT Broker (Mosquitto) con certificado servidor (self-signed)
- MQTT Broker (Mosquitto) con certificado servidor (self-signed) y certificado en los clientes
- MQTT Broker (Mosquitto) con certificado servidor (Let’s Encrypt)
- Formatos de Certificados: PEM, DER y PKCS#12 y Manipulación de Claves Privadas
Introducción
En este artículo explicamos de manera práctica los formatos más comunes de certificados digitales y cómo manipular las claves privadas asociadas. Conocer estos formatos y comandos te permitirá gestionar correctamente tus certificados para su uso en entornos que requieren seguridad y automatización.
Formatos de Certificados
Formato PEM (Privacy Enhanced Mail)
El formato PEM es legible por humanos, ya que utiliza una codificación Base64 en ASCII. Un certificado en este formato comienza con la línea ----BEGIN CERTIFICATE----. Este es el formato requerido para instalar certificados en el trust store (conjunto de certificados de entidades de confianza).
Formato DER (Distinguished Encoding Rules)
El formato DER es un formato binario, más compacto y no legible directamente. Si al inspeccionar tu certificado no ves la línea inicial típica de PEM, probablemente se trate de un certificado en formato DER.
Conversión de DER a PEM
Para instalar un certificado en el trust store, es necesario que esté en formato PEM. Si dispones de un certificado en formato DER, por ejemplo local-ca.der, puedes convertirlo a PEM usando el siguiente comando:
sudo openssl x509 -inform der -outform pem -in local-ca.der -out local-ca.crtFormato PKCS#12
El formato PKCS#12 permite empaquetar tanto el certificado como la clave privada y, opcionalmente, la certificate chain (secuencia de certificados intermedios que verifican la validez del certificado). Es muy útil para exportar e importar credenciales completas de forma segura, ya que el archivo resultante (normalmente con extensión .p12) puede estar protegido por una contraseña.
Es importante tener en cuenta que, si la clave privada de un certificado no se encuentra dentro de la PKI, no se podrá exportar en formato PKCS#12.
En el entorno de easy-rsa, puedes exportar un certificado y su clave privada en formato PKCS#12 con el siguiente comando:
# sintaxis:
./easyrsa export-p12 <nombre-del-certificado|FQDN>
# ejemplo:
./easyrsa export-p12 mqtt.ymbihq.localManipulación de Claves Privadas
Las claves privadas suelen estar protegidas mediante cifrado simétrico, lo que significa que se necesita una passphrase (contraseña) para descifrarlas y utilizarlas. Esta protección es fundamental para evitar el uso no autorizado de la clave en caso de pérdida o robo. En ocasiones, es necesario eliminar o modificar la passphrase para facilitar su uso en ciertos entornos o automatizaciones.
Eliminar la Passphrase
Para eliminar la passphrase de una clave privada, puedes usar el siguiente comando:
openssl rsa -in [original.key] -out [new.key]Si prefieres realizarlo de manera no interactiva, especificando la contraseña directamente en el comando:
openssl rsa -in original.key -out new.key -passin pass:your_original_passphraseCambiar la Passphrase
Si deseas cambiar la passphrase y proteger la clave con un nuevo cifrado (por ejemplo, AES-256), puedes hacerlo de la siguiente forma:
openssl rsa -aes256 -in original.key -out new.keyCierre
Con la información explicada en este artículo, podrás gestionar y convertir certificados entre formatos PEM y DER, empaquetar tus credenciales en formato PKCS#12 y manipular las claves privadas según tus necesidades. Estos conocimientos te permitirán implementar soluciones seguras y automatizadas en tus entornos de desarrollo y producción.
MQTT Broker (Mosquitto) con certificado servidor (Let’s Encrypt)
Serie
- Gestión de certificados (PKI) – easy-rsa
- MQTT Broker (Mosquitto) con certificado servidor (self-signed)
- MQTT Broker (Mosquitto) con certificado servidor (self-signed) y certificado en los clientes
- MQTT Broker (Mosquitto) con certificado servidor (Let’s Encrypt)
- Formatos de Certificados: PEM, DER y PKCS#12 y Manipulación de Claves Privadas
Introducción
En este post presentamos un proof-of-concept para configurar un broker MQTT utilizando Mosquitto, en el que se implementa TLS gracias a los certificados de Let’s Encrypt. Este método aporta varias ventajas frente a las soluciones tradicionales:
- No requiere exposición pública: El servidor no tiene que estar expuesto a Internet; únicamente el nombre de dominio debe resolverse correctamente en DNS, lo que minimiza la superficie de ataque.
- Facilidad de uso: Con Certbot y herramientas automatizadas (como Just), se simplifica el proceso de emisión y renovación de certificados.
- Rentable: Let’s Encrypt ofrece certificados gratuitos, reduciendo costes operativos.
Esta aproximación es ideal para entornos privados, de desarrollo o pruebas de concepto, donde se desea un equilibrio entre seguridad y comodidad.
Demostración en vídeo
Requisitos
- Nombre de dominio: Un dominio válido (por ejemplo,
mqtt.example.com). - Certbot: Herramienta para obtener certificados de Let’s Encrypt.
- Just: Un command runner que simplifica la ejecución de tareas (consulta el Justfile para ver los comandos disponibles).
- Mosquitto: El software del broker MQTT.
Configuración
Obtención de Certificados con Certbot
Let’s Encrypt permite obtener certificados TLS gratuitos y automatizados. Ten en cuenta que, a diferencia de otras implementaciones, Let’s Encrypt no soporta certificados para clientes, por lo que solo se generará el certificado para el servidor.
Existen dos métodos habituales para validar la propiedad del dominio:
- HTTP-01 Challenge: Requiere disponer de un servidor web en funcionamiento.
- DNS-01 Challenge: Consiste en añadir un registro TXT en el DNS, ideal si no dispones de una IP pública o de un servidor web.
Importante: Asegúrate de que el nombre distinguido (DN) del certificado coincide exactamente con el hostname que usarán los clientes para conectarse y que este se resuelve correctamente en DNS.
Instalación
Para comenzar, crea un entorno virtual e instala Certbot:
uv venv
uv pip install certbotSolicitud del Certificado
Emplea la siguiente sintaxis para solicitar el certificado:
just certbot certonly -m <tu-email> --preferred-challenges dns-01 --manual -d <dominio1>,<dominio2>,...Por ejemplo:
just certbot certonly -m oriol@joor.net --preferred-challenges dns-01 --manual -d mqtt.joor.net,pki.joor.netSi la solicitud es exitosa, los certificados se ubicarán en la ruta:
certbot/config/live/<dominio>Dentro de este directorio encontrarás:
privkey.pem: Tu clave privada.fullchain.pem: La cadena completa de certificados, que es la que se utiliza en la mayoría de las configuraciones de servidor.chain.pem: Certificados intermedios (útiles, por ejemplo, para OCSP stapling en Nginx >=1.3.7).cert.pem: Un certificado que puede generar conflictos en algunos escenarios, por lo que generalmente se recomienda utilizarfullchain.pem.
Para Mosquitto, solo se requerirán los archivos fullchain.pem y privkey.pem.
Ejecución del Broker MQTT
La configuración de Mosquitto ya está preparada para referenciar los certificados emitidos por Let’s Encrypt. Para lanzar el servicio, ejecuta:
just mqttEste comando inicia Mosquitto utilizando el archivo de configuración mosquitto.conf, el cual contiene las rutas correctas a los certificados.
Detalles del Certificado
- Clave Privada (
privkey.pem): Garantiza la identidad segura del servidor. - Cadena Completa (
fullchain.pem): Incluye tanto el certificado del servidor como los certificados intermedios necesarios.
Dado que los clientes suelen confiar en las CA de Let’s Encrypt incluidas en sus sistemas operativos, no es necesario proporcionar un certificado CA adicional en el broker.
Renovación del Certificado
Los certificados de Let’s Encrypt tienen una vigencia de 90 días, por lo que es imprescindible renovarlos periódicamente para mantener la seguridad. Para renovar los certificados, puedes usar:
just certbot renew
# o alternativamente:
just certbot_renewTras la renovación, si las rutas en el archivo de configuración de Mosquitto permanecen iguales, el broker utilizará automáticamente el nuevo certificado al reiniciarse o al hacer un reload de la configuración.
Notas
- Esta configuración es una prueba de concepto. Para entornos de producción, considera automatizar completamente el proceso de renovación y revisar otras medidas de seguridad adicionales.
- Asegúrate de actualizar los registros DNS para que la validación del dominio se realice sin problemas.
- Modifica los archivos de configuración únicamente si comprendes las implicaciones de seguridad asociadas.
Referencias
- Repositorio: github.com/mqtt-server-certbot
- Repositorio: github.com/mqtt-server-n-client-n-server-private-pki
- Repositorio: github.com/mqtt-server-private-pki
- https://mqttx.app/
- https://mqttx.app/docs/cli
- Creating and Using Client Certificates with MQTT and Mosquitto
- Using A Lets Encrypt Certificate on Mosquitto
- SSL and SSL Certificates Explained For Beginners
- Mosquitto.conf man
- How to Configure MQTT over WebSockets with Mosquitto Broker
- Getting the Client’s Real IP When Using the NGINX Reverse Proxy for EMQX
MQTT Broker (Mosquitto) con certificado servidor (self-signed) y certificado en los clientes
Serie
- Gestión de certificados (PKI) – easy-rsa
- MQTT Broker (Mosquitto) con certificado servidor (self-signed)
- MQTT Broker (Mosquitto) con certificado servidor (self-signed) y certificado en los clientes
- MQTT Broker (Mosquitto) con certificado servidor (Let’s Encrypt)
- Formatos de Certificados: PEM, DER y PKCS#12 y Manipulación de Claves Privadas
Descripción del escenario
En este post vamos a explorar la configuración de un bróker MQTT utilizando Mosquitto, implementando seguridad mutua a través de certificados: un certificado auto-firmado para el servidor y certificados específicos para los clientes. Analizaremos paso a paso cómo montar el entorno, partiendo de una configuración mínima que permita el uso tanto de conexiones TCP como de Websockets.
A lo largo del artículo se demostrará de manera detallada el proceso de negociación de la conexión cifrada utilizando OpenSSL como cliente TCP+SSL/TLS, y posteriormente se emplearán los clientes de Mosquitto para suscribirse y publicar mensajes en un tópico de demostración. Además, veremos cómo consumir el servicio mediante un sencillo script en Python y, para cerrar, utilizaremos el cliente EMQ MQTTX desde la consola, que nos permitirá interactuar tanto vía TCP como a través de Websockets.
Este enfoque práctico te ayudará a comprender en profundidad cómo garantizar la seguridad en la comunicación MQTT implementando certificados tanto en el servidor como en los clientes. ¡Comencemos!
Asumciones
Para el desarrollo de este post se asumen los siguientes puntos:
- PKI y easy-rsa: Contamos con los conocimientos básicos sobre la gestión de certificados mediante una PKI, tal como se describe en el post Gestión de certificados (PKI) – easy-rsa. Se asume que la PKI ya está desplegada siguiendo las indicaciones de dicho post y que la configuración se encuentra en el fichero
vars. - Resolución DNS: Se dispone de un servidor DNS que resuelve los nombres de host dentro de nuestra red privada. Aunque es posible modificar el fichero
/etc/hostspara lograrlo, esta práctica se considera menos recomendable en entornos donde se puede optar por una solución DNS adecuada. - Instalación de Mosquitto: Se asume que Mosquitto y sus herramientas/clients están instalados en el sistema operativo que utilizaremos. En este post, todas las demostraciones se llevarán a cabo en Linux Ubuntu 22.04.
Estas asunciones nos permitirán centrarnos en la configuración y uso de certificados en el bróker MQTT sin tener que detallar cada uno de los pasos previos para la creación y administración de la infraestructura de certificados.
Demostración en vídeo
Obtención de los certificados
Partimos de lo descrito en el post: MQTT Broker (Mosquitto) con certificado servidor (self-signed)
Por lo tanto, solo tenemos que crear el certificado para los clientes que vamos a usar. Los del servidor MQTT ya están listos.
# desde la máquina que queramos con easy-rsa instalado
./easyrsa gen-req client.example.tld
# se genera fichero mqtt.example.tld.reqFirma de la petición de certificado
Si no se lanzó la petición de certificado (certificate request) desde el mismo PKI, hay que copiarlo a la máquina del PKI e importarlo. No lo olvidemos. Aunque en soluciones domésticas típicamente todo lo movemos dentro de la misma estructura de directorios de la PKI.
# en la PKI:
## importamos el certificado, si no se ha hecho la petición desde aquí
## se asume que se copió el fichero de certificate request en
## /the-path/client.example.tld.req
./easyrsa import-req /the-path/client.example.tld.req client.example.tld
## esto colocará una copia del fichero .req en la PKI y algunos enlaces.
## Se le pide a la PKI que firme el certificado
./easyrsa sign-req client client.example.tld
### esto generará el fichero .crt necesarios para armar el cliente.Creación y firma de la petición de certificado
En un solo comando, en el caso de hacerlo todo desde la PKI (en un solo servidor) podemos obtener: clave privada, request de certificador y certificado firmado. Este certificado será de tipo cliente.
./easyrsa build-client-full client.example.tld
# sin cifrado de la clave privada:
./easyrsa build-client-full client.example.tld --no-passIMPORTANTE, no tiene sentido hacer este comando si previamente hemos hecho la creación de request, (importación) y firmado.
Si queremos emitir un certificado que sea útil tanto para cliente como para servidor podemos usar:
./easyrsa build-serverClient-full clientserver.example.tld
# sin cifrado de la clave privada:
./easyrsa build-serverClient-full clientserver.example.tld --no-passConfiguración de Mosquitto con certificado servidor y requisito de certificado cliente
Esta configuración es muy sencilla y solo pondrá en marcha un Mosquitto en el puerto TCP/8883 además del puerto WSS/8884.
mosquitto.conf
# mqtt secure
listener 8883 0.0.0.0
cafile certs/ca.crt
keyfile certs/mqtt.example.tld.key
certfile certs/mqtt.example.tld.crt
crlfile certs/pki.example.tld.crl
allow_anonymous true
require_certificate true
# websockets secure
listener 8884 0.0.0.0
protocol websockets
cafile certs/ca.crt
keyfile certs/mqtt.example.tld.key
certfile certs/mqtt.example.tld.crt
crlfile certs/pki.example.tld.crl
require_certificate truePara lanzar el servicio, simplemente debemos usar el comando:
mosquitto -c mosquitto.confCuando lancemos el servicio se nos pedirá la passphrase de la clave privada dos veces, una para cada uno de los listerners que hemos puesto la configuración, el TCP y el WSS.
Por otro lado, si se configura use_subject_as_username en true, se empleará el campo completo del sujeto del certificado como nombre de usuario. En el caso de que use_identity_as_username o use_subject_as_username se encuentren desactivados, el cliente deberá autenticarse mediante los métodos habituales, como la verificación a través de password_file. Asimismo, cualquier certificado expedido por las autoridades indicadas en cafile o capath será considerado válido para la conexión, lo que ofrece una mayor flexibilidad en la emisión y comprobación de los certificados de cliente.
Cuando el parámetro require_certificate de Mosquitto está configurado a true, se exige que el cliente presente un certificado válido para poder conectarse satisfactoriamente al servicio MQTT. En este contexto, los parámetros adicionales use_identity_as_username y use_subject_as_username resultan relevantes: si use_identity_as_username se establece en true, se utilizará el Common Name (CN) extraído del certificado del cliente en lugar del nombre de usuario MQTT para el control de acceso, omitiéndose la contraseña, ya que se asume que únicamente los clientes autenticados disponen de certificados válidos.
Negociación de la conexión (OpenSSL s_client)
OpenSSL es la herramienta que hay por debajo de easy-rsa y la librería de referencia para SSL/TLS; además de disponer de herramientas que nos permitirán depurar enlaces de cifrados. Para este caso de uso usaremos openssl s_client que nos va a permitir ver todos los detalles de la negociación SSL/TLS con el servidor de MQTT.
# self-signed fail chechking
openssl s_client \
-CAfile certs/ca.crt \
mqtt.example.tld:8883
# using my CA, self-signed succesful checking
openssl s_client \
-CAfile certs/ca.crt \
--cert certs/client.example.tld.crt \
--key certs/client.example.tld.key \
mqtt.example.tld:8883En el vídeo de demostración puedes ver más detalles de cómo se analiza la negociación entre el servidor y el cliente.
Clientes Mosquitto
Usando mosquitto_sub y mosquitto_pub se demuestra cómo se intercambia tráfico a través de un enlace cifrado. Nada del otro mundo, pero que en entornos cifrados y para evoluciones de este escenario veremos que tiene algunas limitaciones.
Me suscribo al topic llamado topic1 y esperando que se publiquen mensajes en él:
mosquitto_sub -d \
--cafile pki/ca.crt \
--cert certs/client.example.tld.crt \
--key certs/client.example.tld.key \
-h mqtt.example.tld -p 8883 \
-t topic1 -vPublico un mensaje en el topic con el contenido: value1
mosquitto_pub -d \
--cafile pki/ca.crt \
--cert certs/client.example.tld.crt \
--key certs/client.example.tld.key \
-h mqtt.example.tld -p 8883 \
-t topic1 -m "message1"Cuando lancemos los comandos, se nos pedirá la passphrase de la clave privada. Tanto para publicar como para suscribirnos, ya que ambos necesitan acceso al fichero “certs/client.example.tld.key” que esta cifrado con una clave simétrica.
Clientes desarrollados en Python
Se trata de un par de scripts muy sencillos que solo pretenden ilustrar lo sencillo que es especificar nuestra propia CA en la inicialización de la conexión segura con el servidor MQTT.
# se requiere uv, si no lo tienes instalado:
curl -LsSf https://astral.sh/uv/install.sh | sh
# lanzamos el suscriptor
uv run mqtt_sub.py
# lanzamos el publicador
uv run mqtt_pub.pyClientes MQTTX-cli usando TCP y Websockets
Al lanzar el bróker de MQTT expusimos el endpoint en TCP y el de Websockets, pero no hemos usado el segundo para nada todavía. Así, pues, vamos a aprovechar la potencia del cliente de EMQ llamado MQTTX para repetir las mismas funciones que antes, pero ahora haciendo la suscripción con Websockets y la publicación con TCP.
Este cliente por el moment no soporta protección de cifrado simétrico en la clave privada, así pues primero debemos extraer la clave privada a un nuevo fichero:
# extraer clave privada de fichero cifrado:
openssl rsa -in python_client/certs/client.example.tld.key -out python_client/certs/client.example.tld.key.raw
# para completar el proceso se deberá introducir la clave simétrica
# mqttx-cli using docker
alias mqttx-cli 'docker run --rm \
--entrypoint /usr/local/bin/mqttx \
-v ./pki/ca.crt:/tmp/ca.crt \
-v ./python_client/certs/client.example.tld.crt:/tmp/client.example.tld.crt \
-v ./python_client/certs/client.example.tld.key.raw:/tmp/client.example.tld.key \
emqx/mqttx-cli'
# suscripción
mqttx-cli sub \
--ca /tmp/ca.crt \
--cert /tmp/client.example.tld.crt \
--key /tmp/client.example.tld.key \
-h mqtt.example.tld \
-p 8884 -l wss \
-t topic1
# publicación
mqttx-cli pub \
--ca /tmp/ca.crt \
--cert /tmp/client.example.tld.crt \
--key /tmp/client.example.tld.key \
-h mqtt.example.tld \
-p 8883 -l mqtts \
-t topic1 -m message1Referencias
- Repositorio: github.com/mqtt-server-n-client-n-server-private-pki
- Repositorio: github.com/mqtt-server-private-pki
- https://mqttx.app/
- https://mqttx.app/docs/cli
- Creating and Using Client Certificates with MQTT and Mosquitto
- Using A Lets Encrypt Certificate on Mosquitto
- SSL and SSL Certificates Explained For Beginners
- Mosquitto.conf man
- How to Configure MQTT over WebSockets with Mosquitto Broker
- Getting the Client’s Real IP When Using the NGINX Reverse Proxy for EMQX