Mikrotik as a PPTP server for Android
Reading time: 4 – 6 minutes
Two years ago I installed a Mikrotik Cloud Switch and lately I stoped my pfSense and I started using that switch as my network router, firewall and also as a switch. RouterOS is really powerful and allows to do a lot of things with that hardware. One of those things is set-up a VPN server based on PPTP. This is not the most secure way to create VPNs but usually the only requirement is a little bit of security on top of an IP over IP service that allows us to use local service when we’re in remote. In my case I have a lot of services in my LAN and I need some of them when I’m out of home specially I need to use them from my mobile phone.
Next steps describe how I set-up a PPTP server on my Mikrotik server allowing my Android 6 device (Huawei Mate 8) to connect to my home services through the VPN. Bellow you have a simple schema representing the schenario of the solution:
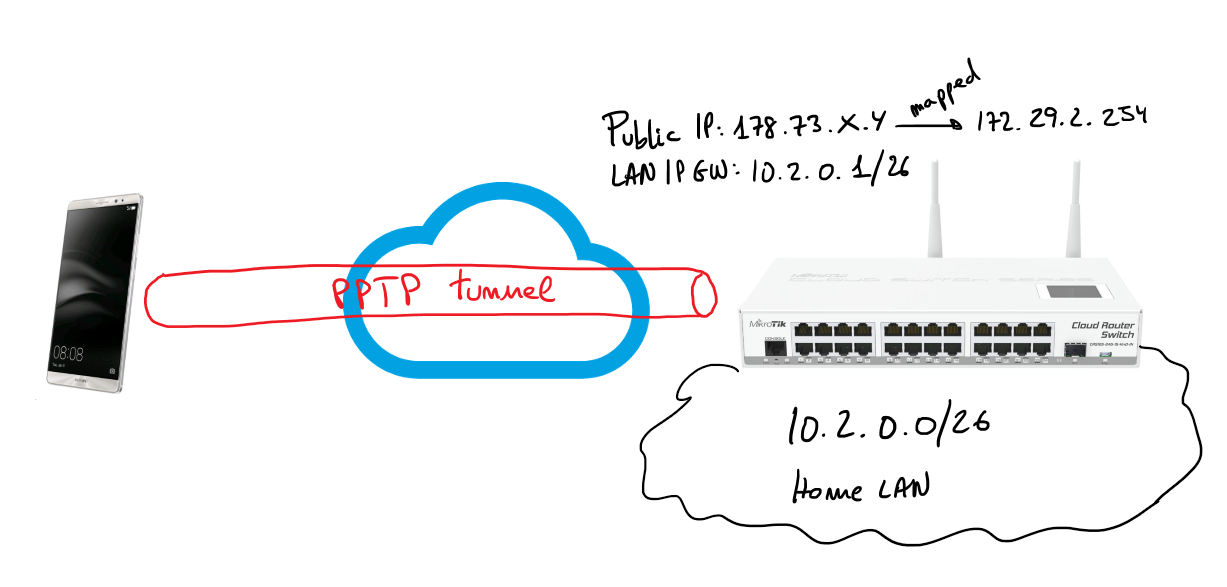
I’m only going to describe steps from the web console, of course, all those steps can be done using Winbox or the command line. To be honest I’m not used to RouterOS CLI but I think it’s not difficult to figure out the CLI commands to get the same result.
First step is set-up a pool of IP addresses to be assigned to the tunnel endpoints.
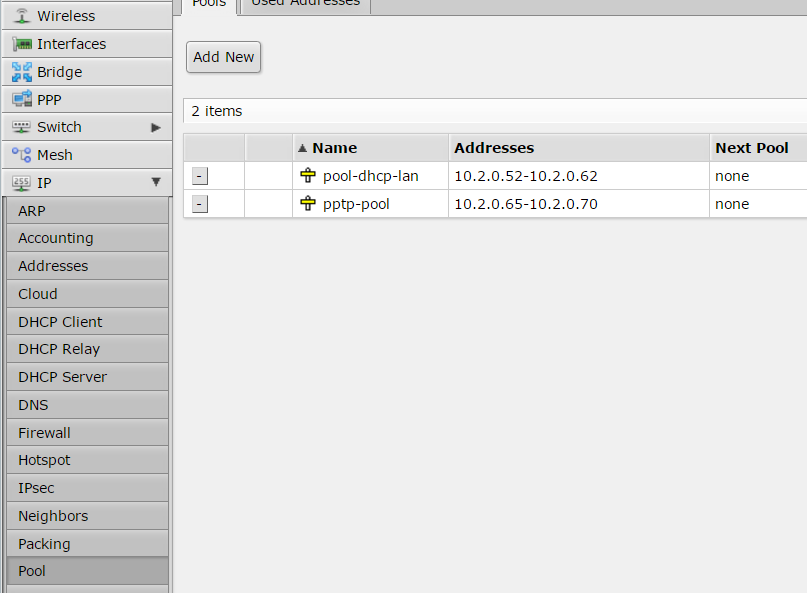
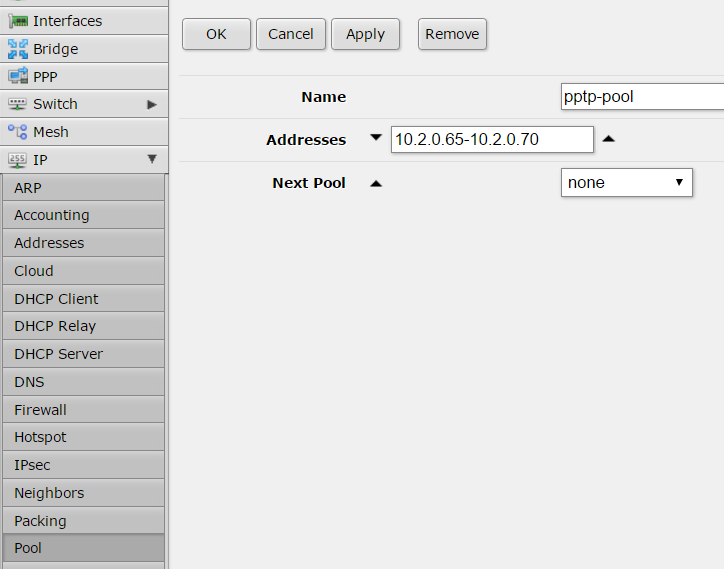
Thanks to an ARP proxy those IP addresses will be available like local IPs, this is transparent for the VPN configuration.
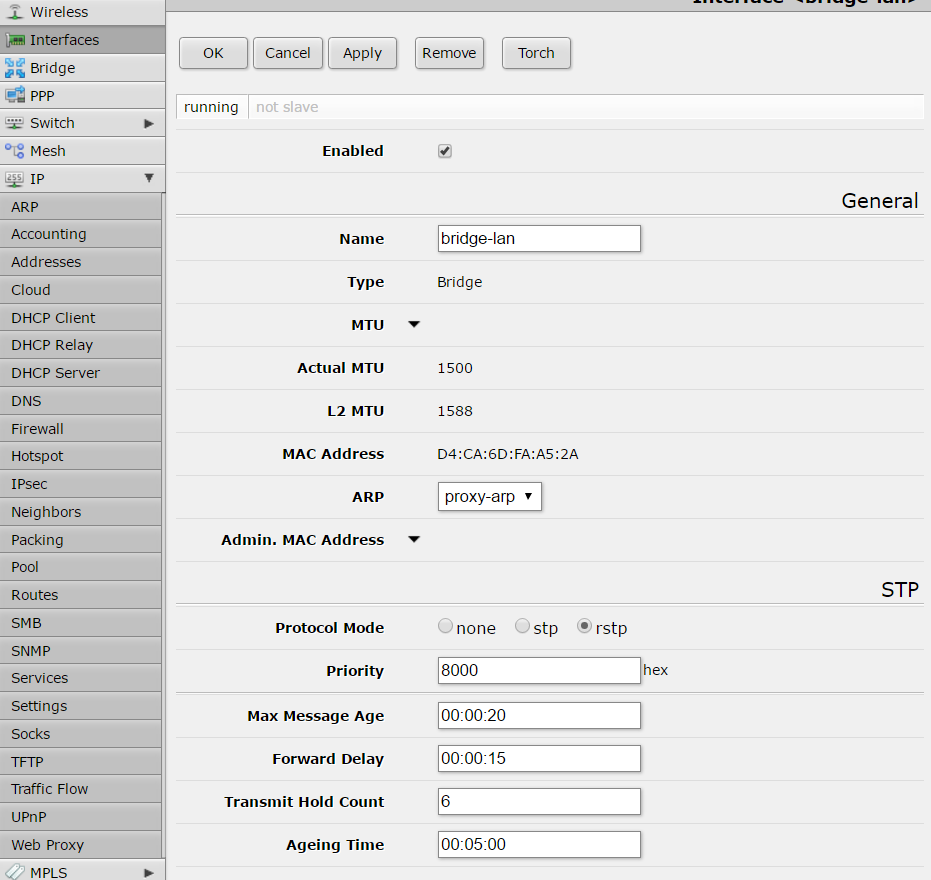
configuration of connection profile is done inside “Profiles” tab:
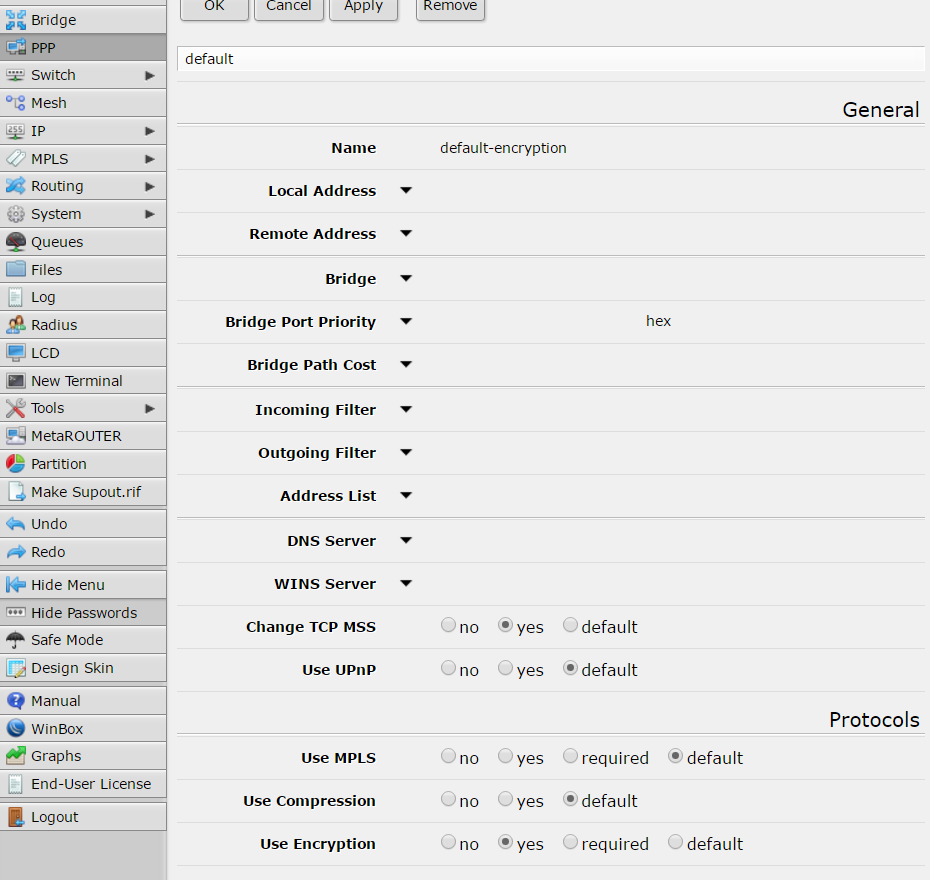
first of all create a new profile called “default-encription”:
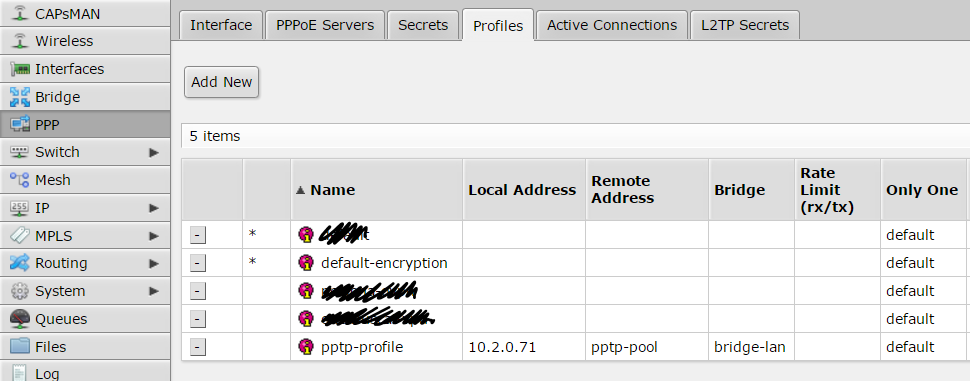
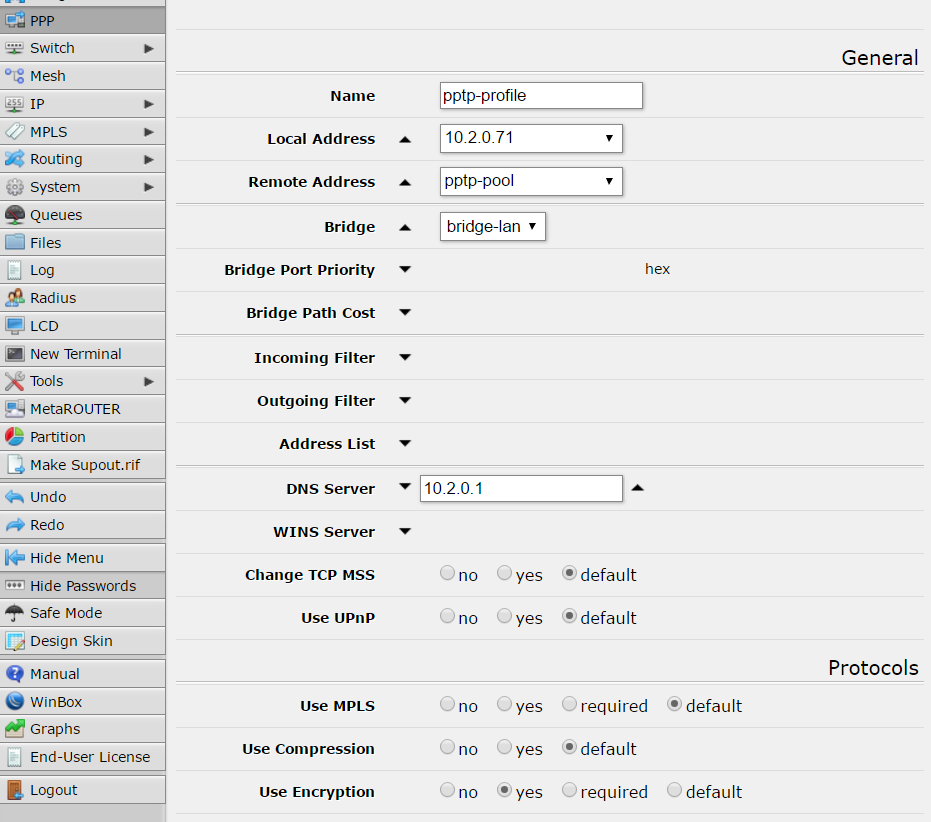
and another profile called “pptp-profile”:
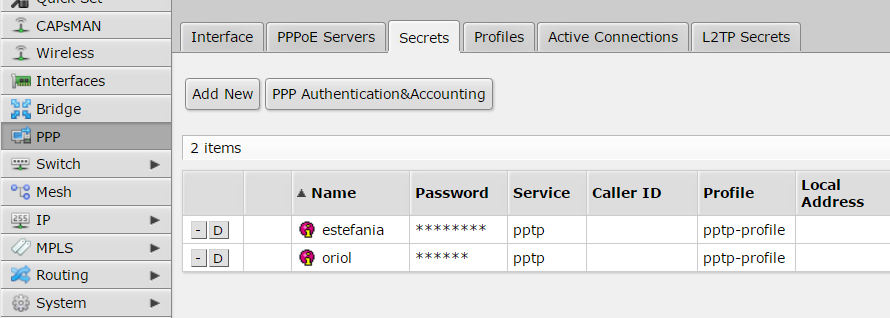
“Secrets” tab is where you have to manage users, in my case only two users are created:
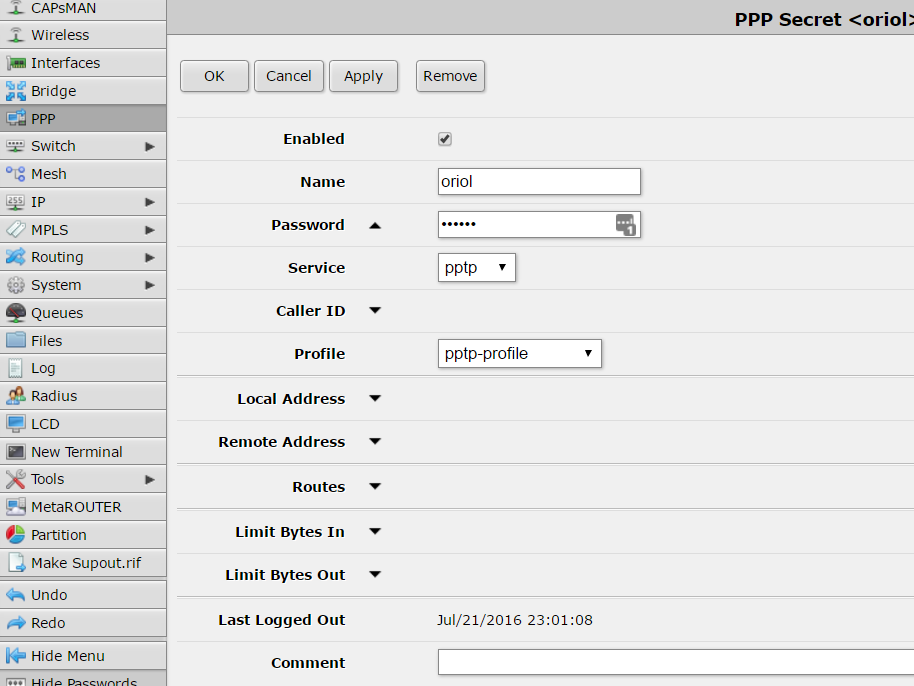
configuration details about my user are:
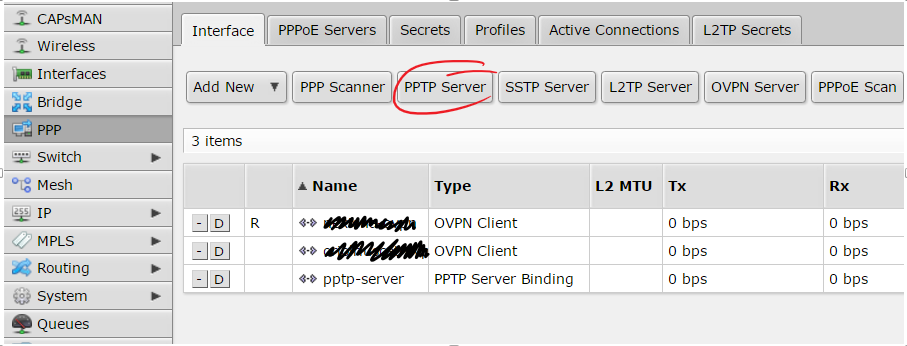
Inside PPP menu there is a button with a label “PPTP server” click there…
… and copy next settings:
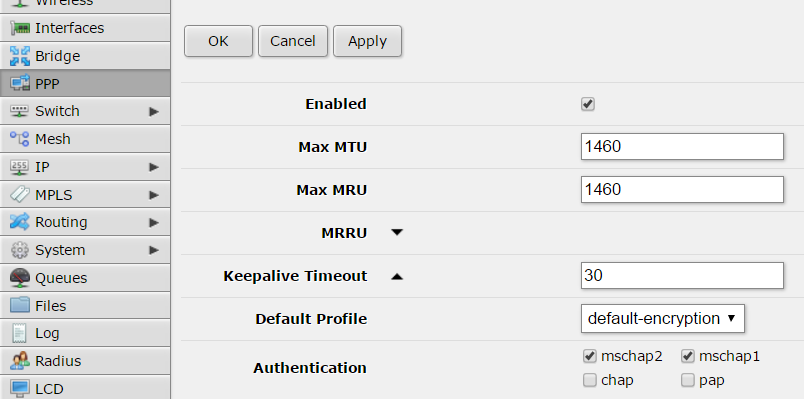
Don’t forget to check that your PPTP port is accessible from your public IP address. Remember it’s 1723/TCP.
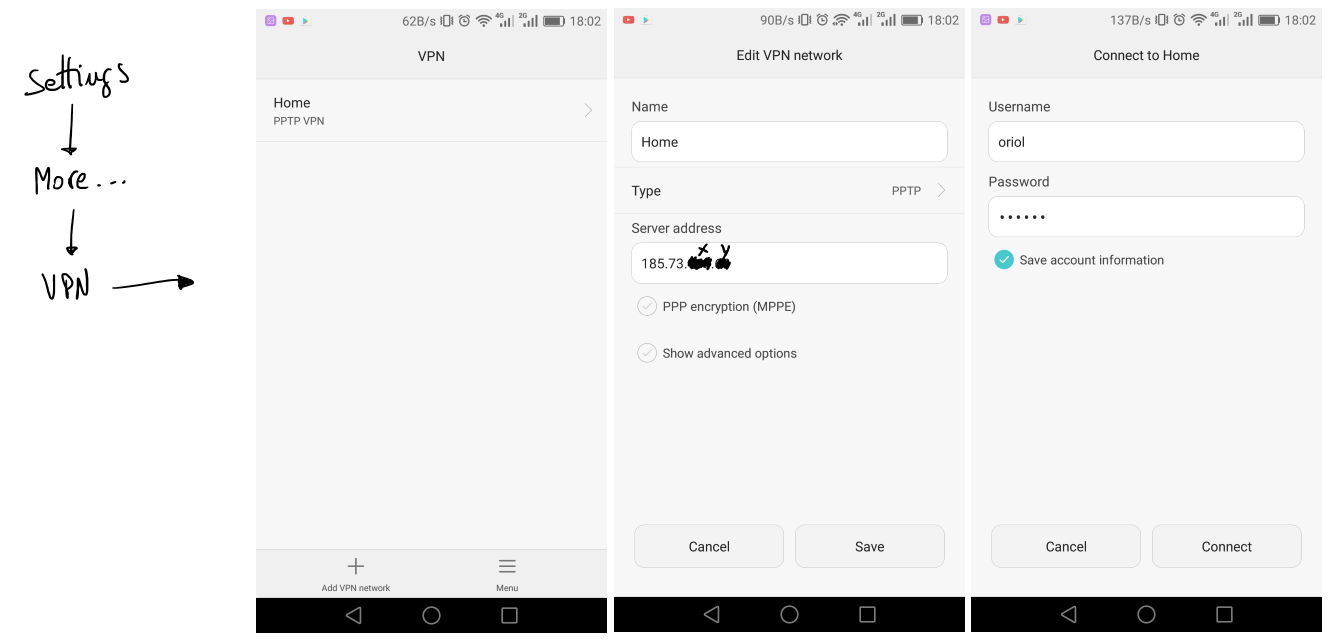
Android configuration is simple, first of all go to “settings” icon. Look for a “More” section bellow network options, and you’ll find VPN managment. Add a new connection, define a name, the type and the IP address and leave the rest by default. After that when you come back to VPN list you’ll find your new VPN in the list, click there and just set-up your PPTP credentials.
If you have some trouble the only thing that you can do is go to Mikrotik logs or start sniffing to figure out where is the problem. I had to do some tests before it was working but in the end everything was so simple like I explained here.
Good luck and enjoy it.
Thanks to next blog entries to inspire me:
- How To Set Up PPTP Server on Mikrotik
- Step by Step: How to configure a PPTP VPN Server on Mikrotik RouterOS