Secure download URLs with expiration time
Reading time: 4 – 6 minutes
Requirements
Imagine a HTTP server with those restrictions:
- only specific files can be downloaded
- with a limited time (expiration date)
- an ID allows to trace who download files
- with minimal maintenance and dependencies (no databases, or things like that)
the base of the solution that I designed is the URL format:
http://URL_HOST/<signature>/<customer_id>/<expire_date>/<path_n_file>
- signature: is calculated with the next formula, given a “seed”
- seed = “This is just a random text.”
- str = customer_id + expire_date + path_n_file
- signature = encode_base64( hmac_sha1( seed, str))
- customer_id: just an arbitrary identifier when you want to distinguish who use the URL
- expire_date: when the generated URL stops working
- path_n_file: relative path in your private repository and the file to share
Understanding the ideas explained before I think it’s enough to understand what is the goal of the solution. I developed the solution using NGINX and LUA. But the NGINX version used is not the default version is a very patched version called Openresty. This version is specially famous because some important Chinese webs works with that, for instance, Taobao.com
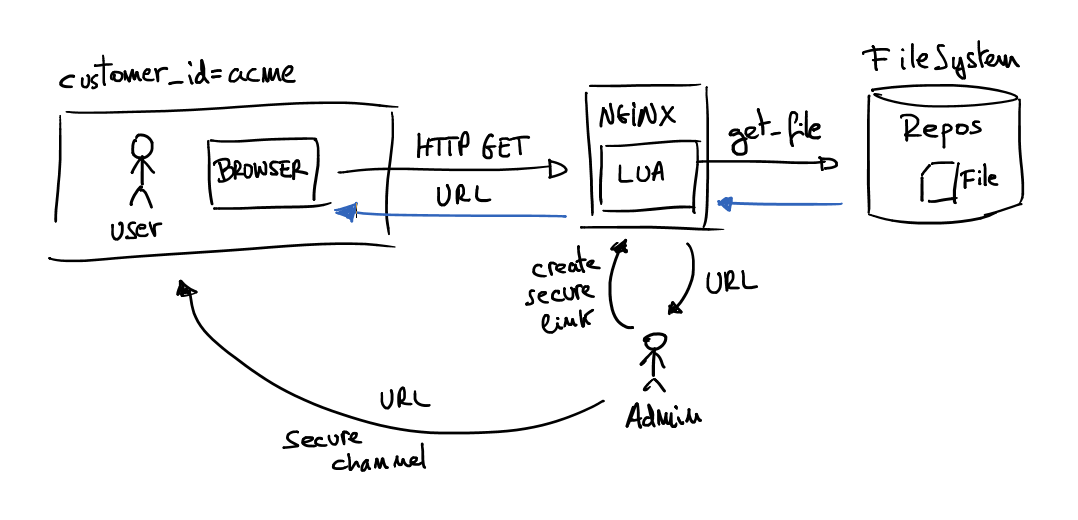
In the above schema there is a master who wants to share a file which is in the internal private repository, but the file has a time restriction and the URL is only for that customer. Then using the command line admin creates a unique URL with desired constrains (expiration date, customer to share and file to share). Next step is send the URL to the customer’s user. When the URL is requested NGINX server evaluates the URL and returns desired file only if the user has a valid URL. It means the URL is not expired, the file already exists, the customer identification is valid and the signature is not modified.
NGINX Configuration
server {
server_name downloads.local;
location ~ ^/(?<signature>[^/]+)/(?<customer_id>[^/]+)/(?<expire_date>[^/]+)/(?<path_n_file>.*)$ {
content_by_lua_file "lua/get_file.lua";
}
location / {
return 403;
}
}
This is the server part of the NGINX configuration file, the rest of the file can as you want. Understanding this file is really simple, because the “server_name” works as always. Then only locations command are relevant. First “location” is just a regular expression which identifies the relevant variables of the URL and passes them to the LUA script. All other URLs that doesn’t match with the URI pattern fall in path “/” and the response is always “Forbiden” (HTTP 403 code). Then magics happen all in LUA code.
LUA scripts
There are some LUA files required:
- create_secure_link.lua: creates secure URLs
- get_file.lua: evaluates URLs and serves content of the required file
- lib.lua: module developed to reuse code between other lua files
- sha1.lua: SHA-1 secure hash computation, and HMAC-SHA1 signature computation in Lua (get from https://github.com/kikito/sha.lua)
It’s required to configure “lib.lua” file, at the beginning of the file are three variables to set up:
lib.secret = "This is just a long string to set a seed" lib.base_url = "http://downloads.local/" lib.base_dir = "/tmp/downloads/"
Create secure URLs is really simple, take look of the command parameters:
$ ./create_secure_link.lua ./create_secure_link.lua <customer_id> <expiration_date> <relative_path/filename> Create URLs with expiration date. customer_id: any string identifying the customer who wants the URL expiration_date: when URL has to expire, format: YYYY-MM-DDTHH:MM relative_path/filename: relative path to file to transfer, base path is: /tmp/downloads/
Run example:
$ mkdir -p /tmp/downloads/dir1 $ echo hello > /tmp/downloads/dir1/example1.txt $ ./create_secure_link.lua acme 2015-08-15T20:30 dir1/example1.txt http://downloads.local/YjZhNDAzZDY0/acme/2015-08-15T20:30/dir1/example1.txt $ date Wed Aug 12 20:27:14 CEST 2015 $ curl http://downloads.local:55080/YjZhNDAzZDY0/acme/2015-08-15T20:30/dir1/example1.txt hello $ date Wed Aug 12 20:31:40 CEST 2015 $ curl http://downloads.local:55080/YjZhNDAzZDY0/acme/2015-08-15T20:30/dir1/example1.txt Link expired
Little video demostration
Resources
- All the code is available in this github project.
Disclaimer and gratefulness
- This is my first code using LUA, I’m sure everything can be done better that I done. Use it at your own risk.
- I want to give thanks to Leaf who wrote a blog post about NGINX and LUA which inspired my solution: Nginx image processing server with OpenResty and Lua.


